
Why Kafka is so fast?
Summary of the article:
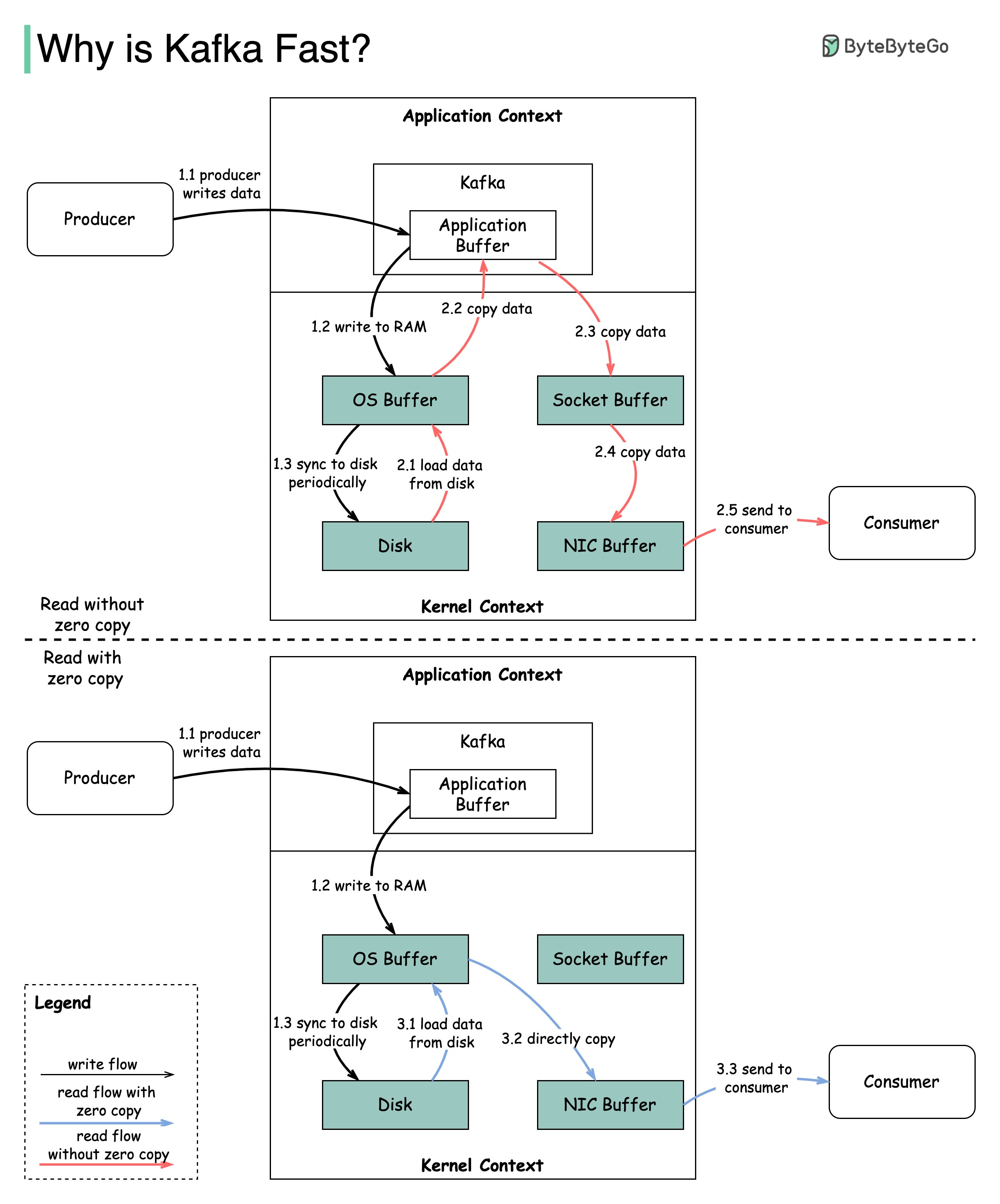
Kafka utilizes a segmented, append-only log, largely limiting itself to sequential I/O for both reads and writes, which is fast across a wide variety of storage media. Kafka generally has better performance. If you are looking for more throughput, Kafka can go up to around 1,000,000 messages per second, whereas the throughput for RabbitMQ is around 4K-10K messages per second. This is due to the architecture, as Kafka was designed around throughput. Kafka can run with a peak throughput of 605 MB/s and p99 latency of 5 ms (200 MB/s load). Kafka is a good substitute for traditional message brokers because it provides higher throughput, built-in partitioning, replication, and fault tolerance, as well as improved scalability capabilities. Kafka is faster than MQ due to its distributed system architecture and better throughput and performance. Spark streaming is better at processing groups of rows, while Kafka streams provide true record-at-a-time processing capabilities, which is better for functions like row parsing and data cleansing. Kafka APIs store data in topics, while REST APIs store data in the database on the server. Kafka is faster than MQ and scales well, but lacks some message simplification and granular security features. Apache Kafka’s main advantage is its massive scalability and low latency. It distributes and replicates partitions across many servers, which protects against server failure. Kafka is faster than JMS as it is a distributed streaming platform that offers high horizontal scalability and high throughput. While IBM MQ has more features, Kafka is better suited for large data frameworks like Lambda and has connectors that provide.
Questions:
- Why Kafka is so fast?
- Why is Kafka faster than RabbitMQ?
- How fast can Kafka run?
- Why Kafka is better than others?
- Why Kafka is faster than MQ?
- Is Kafka faster than Spark?
- Why Kafka is better than REST API?
- Is Kafka faster than MQ?
- What is Kafka main advantage?
- Why Kafka is faster than JMS?
- Can Kafka replace MQ?
Kafka utilizes a segmented, append-only log, largely limiting itself to sequential I/O for both reads and writes, which is fast across a wide variety of storage media.
If you are looking for more throughput, Kafka can go up to around 1,000,000 messages per second, whereas the throughput for RabbitMQ is around 4K-10K messages per second. This is due to the architecture, as Kafka was designed around throughput.
Synopsis of Testing
| Result | |
|---|---|
| Peak Throughput | 605 MB/s |
| p99 Latency | 5 ms (200 MB/s load) |
Kafka is a good substitute for traditional message brokers because it provides higher throughput, built-in partitioning, replication, and fault tolerance, as well as improved scalability capabilities.
Kafka is a distributed system, which allows it to process massive amounts of data. It won’t slow down with the addition of new consumers. Due to the replication of partitions, Kafka easily scales, offering higher availability. But speed is not the only thing to consider.
Spark streaming is better at processing groups of rows (groups, by, ml, window functions, etc.), while Kafka streams provide true record-at-a-time processing capabilities. It’s better for functions like row parsing, data cleansing, etc.
Kafka APIs store data in topics. With REST APIs, you can store data in the database on the server. With Kafka API, you often are not interested in a response. You are typically expecting a response back when using REST APIs.
Apache Kafka scales well and may track events but lacks some message simplification and granular security features. It is perhaps an excellent choice for teams that emphasize performance and efficiency. IBM MQ is a powerful conventional message queue system, but Apache Kafka is faster.
Apache Kafka is massively scalable because it allows data to be distributed across multiple servers, and it’s extremely fast because it decouples data streams, which results in low latency. It can also distribute and replicate partitions across many servers, which protects against server failure.
Kafka is a distributed streaming platform that offers high horizontal scalability. Also, it provides high throughput and that’s why it’s used for real-time data processing. JMS is a general-purpose messaging solution that supports various messaging protocols. Kafka is way faster than JMS.
As a conventional Message Queue, IBM MQ has more features than Kafka. IBM MQ also supports JMS, making it a more convenient alternative to Kafka. Kafka, on the other side, is better suited to large data frameworks such as Lambda. Kafka also has connectors and provides
Why Kafka is so fast medium
Kafka utilizes a segmented, append-only log, largely limiting itself to sequential I/O for both reads and writes, which is fast across a wide variety of storage media.
Cached
Why is Kafka faster than RabbitMQ
Kafka generally has better performance. If you are looking for more throughput, Kafka can go up to around 1,000,000 messages per second, whereas the throughput for RabbitMQ is around 4K-10K messages per second. This is due to the architecture, as Kafka was designed around throughput.
Cached
How fast can Kafka run
Synopsis of Testing
| Result | |
|---|---|
| Peak Throughput | 605 MB/s |
| p99 Latency | 5 ms (200 MB/s load) |
Why Kafka is better than others
Kafka is a good substitute for traditional message brokers because it provides higher throughput, built-in partitioning, replication, and fault tolerance, as well as improved scalability capabilities.
Cached
Why Kafka is faster than MQ
Kafka Has Better Throughput and Performance
Kafka is a distributed system, which allows it to process massive amounts of data. It won't slow down with the addition of new consumers. Due to the replication of partitions, Kafka easily scales, offering higher availability. But speed is not the only thing to consider.
Is Kafka faster than Spark
Spark streaming is better at processing groups of rows(groups,by,ml,window functions, etc.) Kafka streams provide true a-record-at-a-time processing capabilities. it's better for functions like row parsing, data cleansing, etc.
Why Kafka is better than REST API
Kafka APIs store data in topics. With REST APIs, you can store data in the database on the server. With Kafka API, you often are not interested in a response. You are typically expecting a response back when using REST APIs.
Is Kafka faster than MQ
Apache Kafka scales well and may track events but lacks some message simplification and granular security features. It is perhaps an excellent choice for teams that emphasize performance and efficiency. IBM MQ is a powerful conventional message queue system, but Apache Kafka is faster.
What is Kafka main advantage
Apache Kafka is massively scalable because it allows data to be distributed across multiple servers, and it's extremely fast because it decouples data streams, which results in low latency. It can also distribute and replicate partitions across many servers, which protects against server failure.
Why Kafka is faster than JMS
Kafka is a distributed streaming platform that offers high horizontal scalability. Also, it provides high throughput and that's why it's used for real-time data processing. JMS is a general-purpose messaging solution that supports various messaging protocols. Kafka is way faster than JMS.
Can Kafka replace MQ
As a conventional Message Queue, IBM MQ has more features than Kafka. IBM MQ also supports JMS, making it a more convenient alternative to Kafka. Kafka, on the other side, is better suited to large data frameworks such as Lambda. Kafka also has connectors and provides stream processing.