



Why Kafka vs RabbitMQ?
html format without tags html, head, body, title:
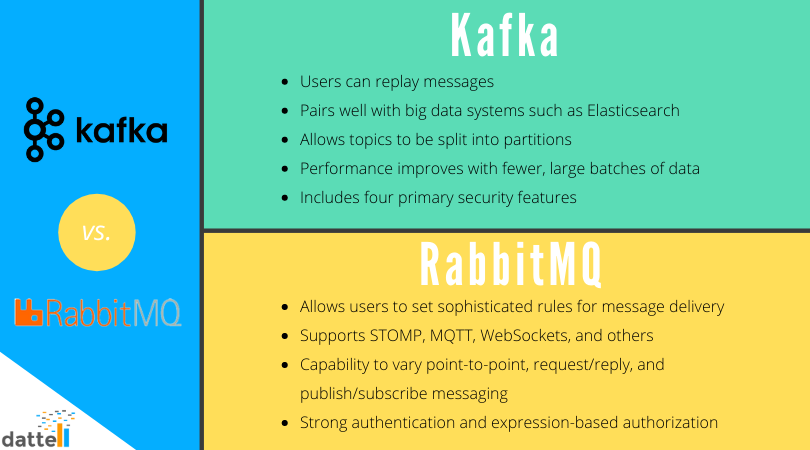
Advantages of Kafka over RabbitMQ
Kafka offers much higher performance than message brokers like RabbitMQ. It uses sequential disk I/O to boost performance, making it a suitable option for implementing queues. It can achieve high throughput (millions of messages per second) with limited resources, a necessity for big data use cases.
Why Kafka is preferred
Apache Kafka is able to handle many terabytes of data without incurring much at all in the way of overhead. Kafka is highly durable. Kafka persists the messages on the disks, which provides intra-cluster replication.
Why choose Kafka over MQ
Kafka Has Better Throughput and Performance
Kafka is a distributed system, which allows it to process massive amounts of data.
It won’t slow down with the addition of new consumers. Due to the replication of partitions, Kafka easily scales, offering higher availability. But speed is not the only thing to consider.
Disadvantages of RabbitMQ
RabbitMQ offers reliability, flexible routing, multiple exchange types, and easy deployment for enhanced messaging systems.
RabbitMQ drawbacks: overly technical, limited queue visibility, and unclear error messages.
Downside of Kafka
Disadvantages Of Apache Kafka
Do not have a complete set of monitoring tools: Apache Kafka does not contain a complete set of monitoring as well as managing tools. Thus, new startups or enterprises fear to work with Kafka. Message tweaking issues: The Kafka broker uses system calls to deliver messages to the consumer.
Why Kafka is better than REST API
Kafka APIs store data in topics. With REST APIs, you can store data in the database on the server.
With Kafka API, you often are not interested in a response. You are typically expecting a response back when using REST APIs.
Why use Kafka for microservices
Using Kafka for asynchronous communication between microservices can help you avoid bottlenecks that monolithic architectures with relational databases would likely run into.
Because Kafka is highly available, outages are less of a concern and failures are handled gracefully with minimal service interruption.
Why use Kafka instead of REST API
The purpose of APIs is to essentially provide a way to communicate between different services, development sides, microservices, etc.
The REST API is one of the most popular API architectures out there. But when you need to build an event streaming platform, you use the Kafka API.
Why use Kafka instead of a database
Kafka has similar properties to a database; however, Kafka stores data as a series of events while other databases co-locate data based on the keys and indexes to facilitate fast lookup.
In a database, key indexes are assigned at the table or document level, whereas in Kafka, keys are assigned at the message level.
Why is Kafka faster than RabbitMQ
Kafka generally has better performance. If you are looking for more throughput, Kafka can go up to around 1,000,000 messages per second, whereas the throughput for RabbitMQ is around 4K-10K messages per second.
This is due to the architecture, as Kafka was designed around throughput.
Why use RabbitMQ in Microservices
The event bus implementation with RabbitMQ lets microservices communicate asynchronously and reliably.
It provides a decoupled architecture where services can communicate through messages, enabling scalability and flexibility.
What are the advantages of Kafka over RabbitMQ
Kafka offers much higher performance than message brokers like RabbitMQ. It uses sequential disk I/O to boost performance, making it a suitable option for implementing queues. It can achieve high throughput (millions of messages per second) with limited resources, a necessity for big data use cases.
Cached
Why Kafka is preferred
Apache Kafka is able to handle many terabytes of data without incurring much at all in the way of overhead. Kafka is highly durable. Kafka persists the messages on the disks, which provides intra-cluster replication.
Cached
Why choose Kafka over MQ
Kafka Has Better Throughput and Performance
Kafka is a distributed system, which allows it to process massive amounts of data. It won't slow down with the addition of new consumers. Due to the replication of partitions, Kafka easily scales, offering higher availability. But speed is not the only thing to consider.
What are the disadvantages of RabbitMQ
RabbitMQ offers reliability, flexible routing, multiple exchange types, and easy deployment for enhanced messaging systems. RabbitMQ drawbacks: overly technical, limited queue visibility, and unclear error messages.
What is the downside of Kafka
Disadvantages Of Apache Kafka
Do not have complete set of monitoring tools: Apache Kafka does not contain a complete set of monitoring as well as managing tools. Thus, new startups or enterprises fear to work with Kafka. Message tweaking issues: The Kafka broker uses system calls to deliver messages to the consumer.
Why Kafka is better than REST API
Kafka APIs store data in topics. With REST APIs, you can store data in the database on the server. With Kafka API, you often are not interested in a response. You are typically expecting a response back when using REST APIs.
Why use Kafka for microservices
Using Kafka for asynchronous communication between microservices can help you avoid bottlenecks that monolithic architectures with relational databases would likely run into. Because Kafka is highly available, outages are less of a concern and failures are handled gracefully with minimal service interruption.
Why use Kafka instead of REST API
The purpose of APIs is to essentially provide a way to communicate between different services, development sides, microservices, etc. The REST API is one of the most popular API architectures out there. But when you need to build an event streaming platform, you use the Kafka API.
Why use Kafka instead of database
Kafka has similar properties to a database, however, Kafka stores data as a series of events while other database's co-locate data based on the keys and indexes to facilitate fast lookup. In a database key, indexes are assigned at the table or document level, whereas in Kafka, keys are assigned at the message level.
Why is Kafka faster than RabbitMQ
Kafka generally has better performance. If you are looking for more throughput, Kafka can go up to around 1,000,000 messages per second, whereas the throughput for RabbitMQ is around 4K-10K messages per second. This is due to the architecture, as Kafka was designed around throughput.
Why use RabbitMQ in Microservices
The event bus implementation with RabbitMQ lets microservices subscribe to events, publish events, and receive events, as shown in Figure 6-21. RabbitMQ functions as an intermediary between message publisher and subscribers, to handle distribution.
Where Kafka should not be used
It's best to avoid using Kafka as the processing engine for ETL jobs, especially where real-time processing is needed. That said, there are third-party tools you can use that work with Kafka to give you additional robust capabilities – for example, to optimize tables for real-time analytics.
What is difference between RabbitMQ and Kafka
RabbitMQ uses a distinct, bounded data flow. Messages are created and sent by the producer and received by the consumer. Apache Kafka uses an unbounded data flow, with the key-value pairs continuously streaming to the assigned topic.
What is the advantage of Kafka over database
Kafka has similar properties to a database, however, Kafka stores data as a series of events while other database's co-locate data based on the keys and indexes to facilitate fast lookup. In a database key, indexes are assigned at the table or document level, whereas in Kafka, keys are assigned at the message level.
Should I use Kafka or RabbitMQ for microservices
RabbitMQ is best for transactional data, such as order formation and placement, and user requests. Kafka works best with operational data like process operations, auditing and logging statistics, and system activity.
Why not use Kafka as database
Kafka's data storage is a little different from how a database functions. Because of its streaming services, users consume data on this platform using tail reads. It does not rely much on disk reads as a database would because it wants to leverage the page cache to serve the data.
Which is more popular Kafka or RabbitMQ
Kafka is best for big data cases that require extremely fast throughput. With its retention policies, it is also good for clients that want to connect and get a history of messages to replay. RabbitMQ would be the better option in situations where complex routing and low latency delivery is needed.
Why use Kafka for microservice
Using Kafka for asynchronous communication between microservices can help you avoid bottlenecks that monolithic architectures with relational databases would likely run into. Because Kafka is highly available, outages are less of a concern and failures are handled gracefully with minimal service interruption.
What is the reason for using RabbitMQ
RabbitMQ is a widely used open-source message broker that helps in scaling the application by deploying a message queuing mechanism in between the two applications. It offers temporary storage for data preventing data loss. RabbitMQ Queue takes messages from the publisher and sends them to the consumer.
What are the disadvantages of using Kafka
Disadvantages Of Apache KafkaDo not have complete set of monitoring tools: Apache Kafka does not contain a complete set of monitoring as well as managing tools.Message tweaking issues: The Kafka broker uses system calls to deliver messages to the consumer.
Why does Netflix use Kafka
Kafka acts as a bridge for all point-to-point and Netflix Studio wide communications. It provides us with the high durability and linearly scalable, multi-tenant architecture required for operating systems at Netflix.
Is Kafka push or pull based
One of the primary differences between the two is that Kafka is pull-based, while RabbitMQ is push-based. A pull-based system waits for consumers to ask for data.
Is Kafka good for message queue
In short, Kafka is a message queuing system with a couple of twists. It offers low-latency message processing just like a great message queue, along with high availability and fault tolerance, but it brings additional possibilities that simple queuing can't offer.
What is the disadvantage of Kafka
Disadvantages of KafkaDoesn't possess a full set of management and monitoring tools.The broker uses certain system calls to deliver messages to the consumer, but if the message needs some tweaking, doing so reduces Kafka's performance significantly.
Why Kafka is so fast
Kafka stores all the data it ingests in a log-structured format, which means that new data is appended to the end of the log. This allows for very fast writes, since only the latest data needs to be appended, but it also means that older data needs to be periodically compacted to reclaim disk space.