



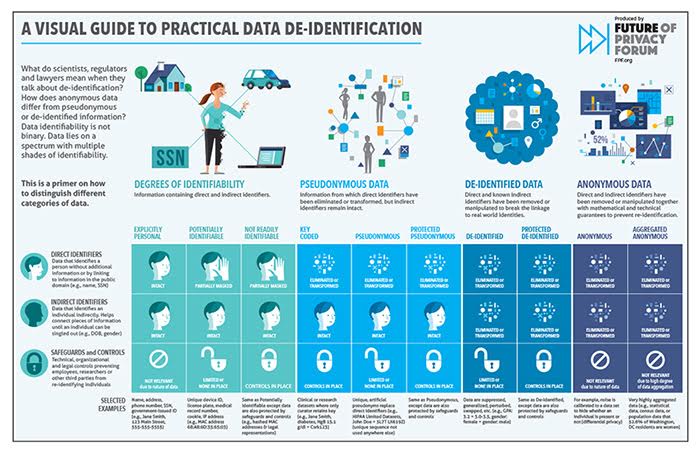
Qual è la differenza tra de-identificato e anonimo?
Riepilogo dell’articolo
Cosa èconsiderato de-identificato
I dati de-identificati descrivono i record che hanno un codice di re-identificazione e
avere abbastanza informazioni identificabili personalmente rimosse o oscurate in modo che le informazioni rimanenti non lo facciano
identificare un individuo e non vi è alcuna base ragionevole per credere che le informazioni possano essere utilizzate per identificare un
individuale.
[/WPREMARK]
Cosa èLa differenza tra de-identificata e pseudonimizzata
Ciò differisce dai dati de-identificati, che è
dati che possono essere collegati a individui che utilizzano un codice, un algoritmo o uno pseudonimo. Definizione chiave: “pseudonimizzazione” di
I dati si riferiscono a una procedura attraverso la quale gli identificatori personali in una serie di informazioni sono sostituiti con artificiale
identificatori o pseudonimi. Cache
[/WPREMARK]
Che cosasignifica de-anonimizza
La de-anonimizzazione è una strategia di data mining in cui sono i dati anonimi
referenziata con altre fonti di dati per re-identificare l’origine dati anonima. Qualsiasi informazione che
Distingue una fonte di dati da un’altra può essere utilizzata per la de-anonimizzazione.
[/WPREMARK]
Che cosaI dati dei pazienti de-identificati significano
I dati del paziente de-identificati sono le informazioni del paziente che hanno avuto
informazioni identificabili personalmente (pii; e.G. Il nome di una persona, l’indirizzo e -mail o il numero di previdenza sociale), incluso
Informazioni sanitarie protette (phi; e.G. Storia medica, risultati dei test e informazioni assicurative) rimossi.
[/WPREMARK]
Che cosaè un esempio di dati de-identificati
Numeri di conto. Numeri beneficiari del piano sanitario.
Numeri di certificato/licenza. Identificatori del veicolo e numeri di serie, comprese le targhe.
[/WPREMARK]
Che cosasono i due tipi di metodi di de-identificazione
Tecniche. Le strategie comuni di de-identificazione sono
mascherare gli identificatori personali e generalizzare quasi identificatori.
[/WPREMARK]
Che cosaè l’opposto dei dati de-identificati
Il processo inverso dell’utilizzo dei dati de-identificati per identificare
Gli individui sono conosciuti come re-identificazione dei dati.
[/WPREMARK]
Che cosaè pseudonimizzato vs dati anonimi
Con anonimizzazione, i dati vengono cancellati per qualsiasi informazione che
può servire da identificatore di un soggetto di dati. La pseudonimizzazione non rimuove tutte le informazioni identificative da
dati ma riducono semplicemente la collegamento di un set di dati con l’identità originale di un individuo (E.G., Via un
Schema di crittografia).
[/WPREMARK]
Che cosaè un esempio di de-anonimizzazione
Probabilmente il migliore coinvolge la popolare piattaforma di streaming
Netflix e risale al 2006. All’epoca, i ricercatori dell’Università del Texas hanno de-anonimizzato un gran numero di
Gli utenti di Netflix fanno riferimenti incrociati con le valutazioni dei film con le recensioni lasciate sul database di film Internet (IMDB).
[/WPREMARK]
Che cosaè un esempio di dati anonimi
Un esempio di dati anonimi è un set di dati che è stato spogliato
di qualsiasi informazione personalmente identificabile come nomi, indirizzi e numeri di telefono. Questo tipo di dati può essere
Utilizzato per analizzare le tendenze e i modelli senza il rischio di esporre le informazioni personali di qualsiasi individuo.
[/WPREMARK]
Che cosasono dati anonimi a livello di paziente
APLD:- Dati a livello di paziente anonimo, dati per RX e DX in un paziente
Livello in cui non conosciamo il nome del paziente e i suoi dettagli della paziente ma è identificato da un ID paziente univoco.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Ciò che è considerato de-identificato
I dati de-identificati descrivono i record che hanno un codice di re-identificazione e hanno abbastanza informazioni identificabili personalmente rimosse o oscurate in modo che le informazioni rimanenti non identifichino un individuo e non vi siano basi ragionevoli per credere che le informazioni possano essere utilizzate per identificare un individuo.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Qual è la differenza tra deidentificato e pseudonimo
Ciò differisce dai dati de-identificati, che sono dati che possono essere collegati a individui che utilizzano un codice, algoritmo o pseudonimo. Definizione chiave: “pseudonimizzazione” dei dati si riferisce a una procedura attraverso la quale gli identificatori personali in una serie di informazioni sono sostituiti con identificatori artificiali o pseudonimi.
Cache
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Cosa significa de AnonyMize
La de-anonimizzazione è una strategia di data mining in cui i dati anonimi sono trasmessi con altre fonti di dati per identificare l’origine dati anonima. Qualsiasi informazione che distingue una fonte di dati dall’altra può essere utilizzata per la de-anonimizzazione.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Cosa significano i dati dei pazienti deidentificati
I dati del paziente de-identificati sono le informazioni sul paziente che hanno avuto informazioni di identificazione personale (PII; e.G. Il nome di una persona, l’indirizzo e -mail o il numero di previdenza sociale), comprese le informazioni sanitarie protette (phi; e.G. Storia medica, risultati dei test e informazioni assicurative) rimossi.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Cos’è un esempio di dati deidentificati
Numeri di conto. Numeri beneficiari del piano sanitario. Numeri di certificato/licenza. Identificatori del veicolo e numeri di serie, comprese le targhe.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Quali sono i due tipi di metodi di de-identificazione
Tecniche. Le strategie comuni di de-identificazione sono mascherare gli identificatori personali e generalizzare i quasi identificatori.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Qual è l’opposto dei dati deidentificati
Il processo inverso dell’utilizzo dei dati de-identificati per identificare le persone è noto come re-identificazione dei dati.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Cosa sono dati pseudonimizzati vs anonimi
Con anonimizzazione, i dati vengono cancellati per qualsiasi informazione che possa fungere da identificatore di un soggetto di dati. La pseudonimizzazione non rimuove tutte le informazioni identificative dai dati ma riduce semplicemente la collegamento di un set di dati con l’identità originale di un individuo (E.G., tramite uno schema di crittografia).
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Cos’è un esempio di de anonimizzazione
Probabilmente il migliore coinvolge la famosa piattaforma di streaming Netflix e risale al 2006. All’epoca, i ricercatori dell’Università del Texas hanno de-anonimizzato un gran numero di utenti di Netflix facendo riferimenti incrociati con le valutazioni dei film con le recensioni lasciate sul database di film Internet (IMDB).
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Cos’è un esempio di dati anonimi
Un esempio di dati anonimi è un set di dati che è stato spogliato di qualsiasi informazione personalmente identificabile come nomi, indirizzi e numeri di telefono. Questo tipo di dati può essere utilizzato per analizzare tendenze e modelli senza il rischio di esporre le informazioni personali di qualsiasi individuo.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Cosa sono i dati anonimi a livello di paziente
APLD:- Dati a livello di paziente anonimo, dati per RX e DX a livello del paziente in cui non conosciamo il nome del paziente e i dettagli del suo paziente ma è identificato da un ID paziente univoco.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Come si deidentifichi i dati del paziente
5 passaggi per la rimozione degli identificatori da DataSetsReview e rimuovere gli identificatori diretti.Rimuovere e ri-codificare le date specifiche.Rimuovere e ri-codificare le variabili geografiche.Rimuovi / Recode le variabili che rappresentano il rischio di collegamento a set di dati esterni.Ripristinare e rinombrare i record e gli ID da dati di origine esterna e ID creati per il tuo studio.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Quali sono esempi di dati anonimi
Un esempio di dati anonimi è un set di dati che è stato spogliato di qualsiasi informazione personalmente identificabile come nomi, indirizzi e numeri di telefono. Questo tipo di dati può essere utilizzato per analizzare tendenze e modelli senza il rischio di esporre le informazioni personali di qualsiasi individuo.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Per cosa sono i dati deidentificati utilizzati
I dati de-identificati possono essere utilizzati nella ricerca medica e nel trattamento. Una volta che l’identificazione delle informazioni viene rimossa, i dati possono fornire informazioni utili per l’avanzamento dell’assistenza sanitaria.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Qual è l’opposto di Anonimizzato
La de-anonimizzazione è il processo inverso in cui i dati anonimi sono trasmessi incrociati con altre fonti di dati per identificare l’origine dati anonima.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Qual è la differenza tra dati deidentificati e codificati
Codificato si riferisce ai dati che nessuno al di fuori di un team di studio può collegarsi all’identità di un soggetto. De-identificato si riferisce ai dati che erano completamente identificabili o codificati, fino a quando il ricercatore non ha distrutto tutti gli identificatori che collega i dati per studiare i soggetti.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] In che modo l’anonimato e la pseudonimato sono diversi
I dati pseudonimi sono dati che sono stati de-identificati dall’argomento dei dati ma possono essere re-identificati secondo necessità. I dati anonimi sono dati che sono stati modificati in modo che la reidentificazione dell’individuo sia impossibile.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Cos’è l’anonimato vs pseudonimato
Qualcuno che è anonimo è in grado di operare o parlare in un modo che li rende non identificabili. Qualcuno che è pseudonimo opera o parla in un modo in cui può essere identificato, ma i loro scudi di identificazione chi sono effettivamente.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Qual è un’altra parola per de anonimizzazione
De-anonimizzazione, anche indicata come re-identificazione dei dati, le informazioni incrociate hanno anonimo con altri dati disponibili al fine di identificare una persona, un gruppo o una transazione.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Come si deidentificano i dati
5 passaggi per la rimozione degli identificatori da DataSetsReview e rimuovere gli identificatori diretti.Rimuovere e ri-codificare le date specifiche.Rimuovere e ri-codificare le variabili geografiche.Rimuovi / Recode le variabili che rappresentano il rischio di collegamento a set di dati esterni.Ripristinare e rinombrare i record e gli ID da dati di origine esterna e ID creati per il tuo studio.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] I dati anonimi possono essere identificati
La ri-identificazione dei dati si verifica quando le informazioni di identificazione personale sono rilevabili nei dati “anonimi” strofinati o cosiddetti “anonimi”. Quando viene identificato un set di dati lavati, gli identificatori diretti o indiretti diventano noti e l’individuo può essere identificato.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Quali sono i due metodi di deidentificazione
Come discusso di seguito, la regola della privacy fornisce due metodi di de-identificazione: 1) una determinazione formale da parte di un esperto qualificato; oppure 2) la rimozione di identificatori individuali specifici e l’assenza di conoscenze effettive da parte dell’entità coperta che le informazioni rimanenti potrebbero essere utilizzate da sole o in combinazione con altri …
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Qual è l’opposto dei dati anonimi
La de-anonimizzazione è il processo inverso in cui i dati anonimi sono trasmessi incrociati con altre fonti di dati per identificare l’origine dati anonima.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Qual è un’altra parola per anonimo
In questa pagina troverai 36 sinonimi, contrari e parole relative ad anonimi, come: senza nome, non divulgato, non identificato, senza nome, senza segno e null.
[/WPREMARK]
[wppremark_icon icon = “quote-left-2-solid” width = ” 32 “altezza =” 32 “] Cos’è un sinonimo di de anonimizzazione
De-anonimizzazione, anche indicata come re-identificazione dei dati, le informazioni incrociate hanno anonimo con altri dati disponibili al fine di identificare una persona, un gruppo o una transazione.
[/WPREMARK]